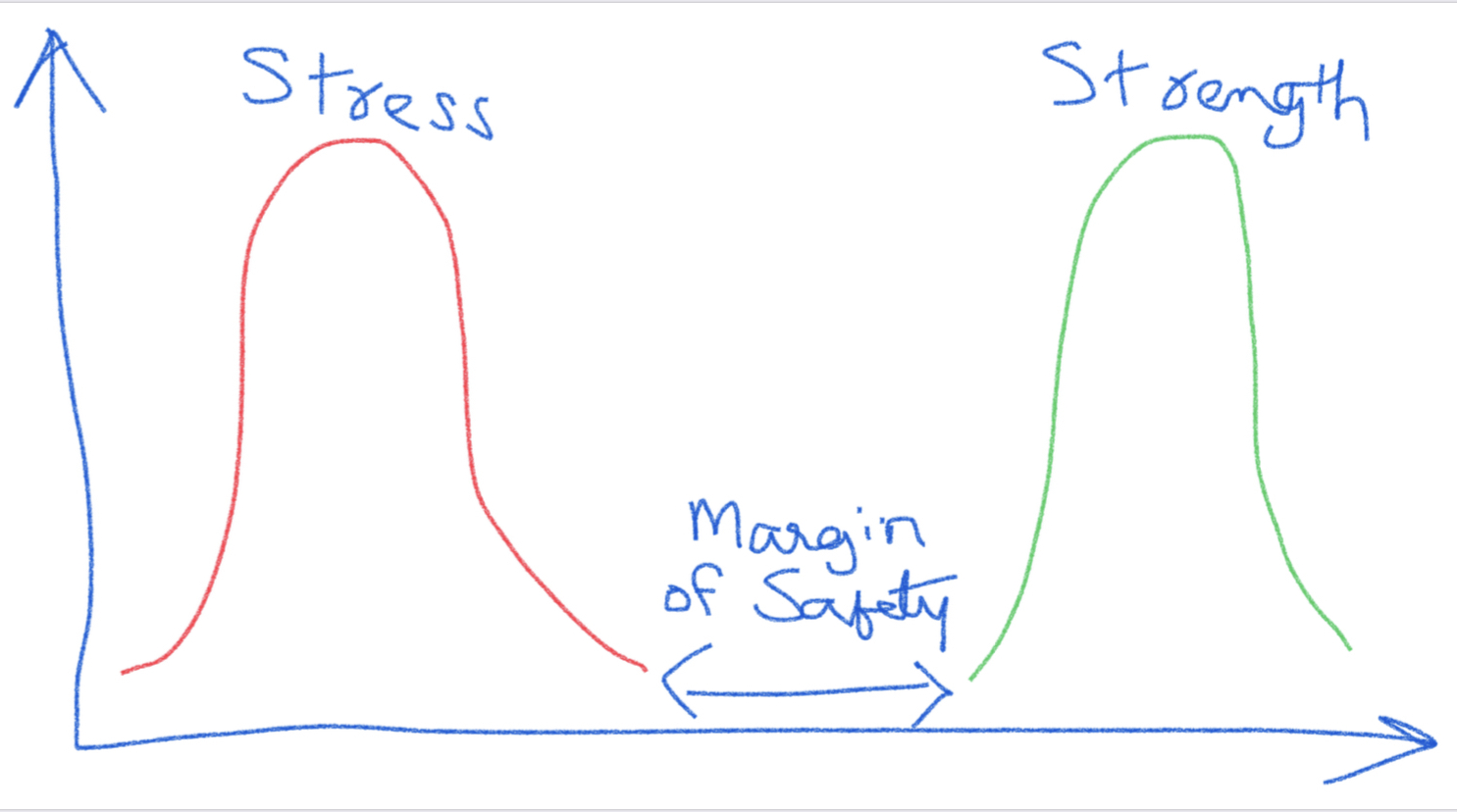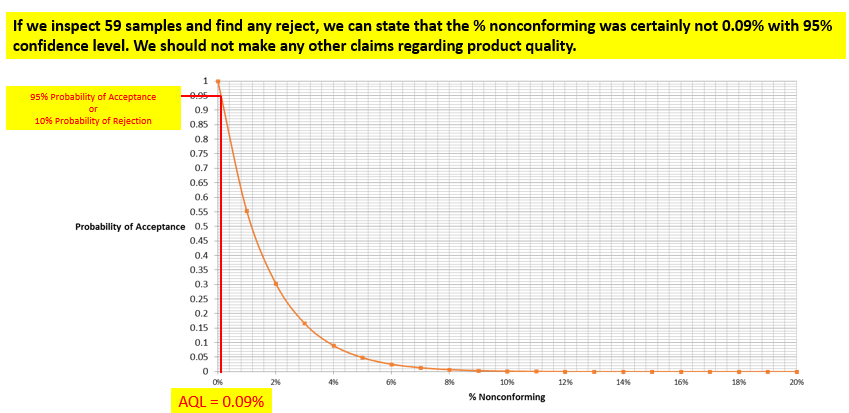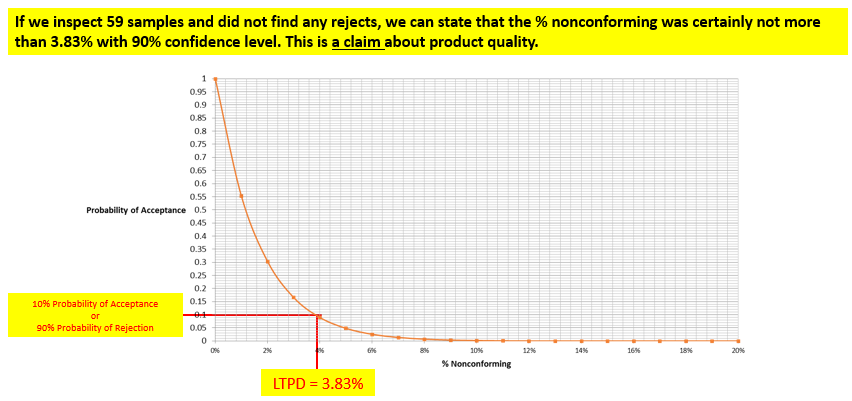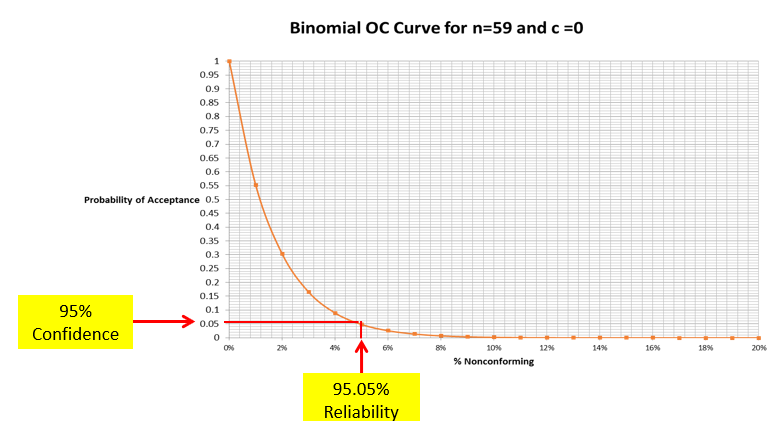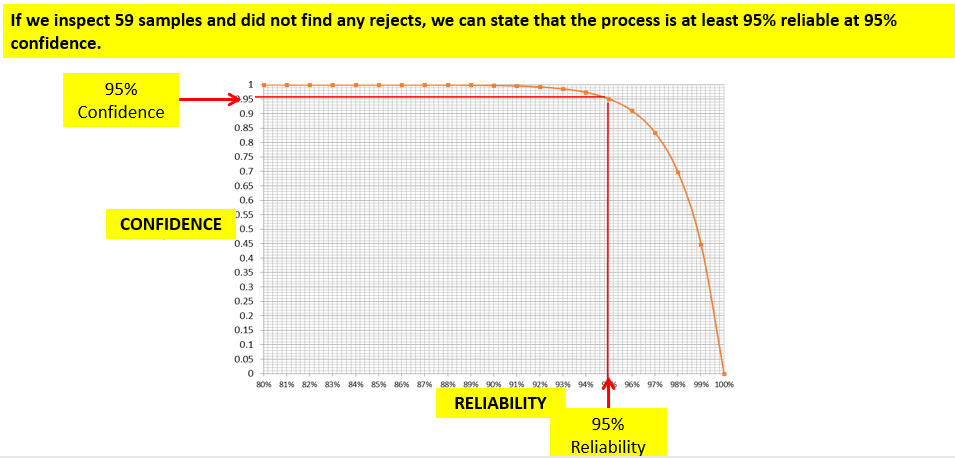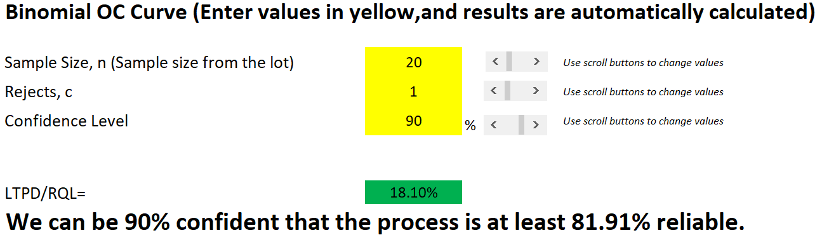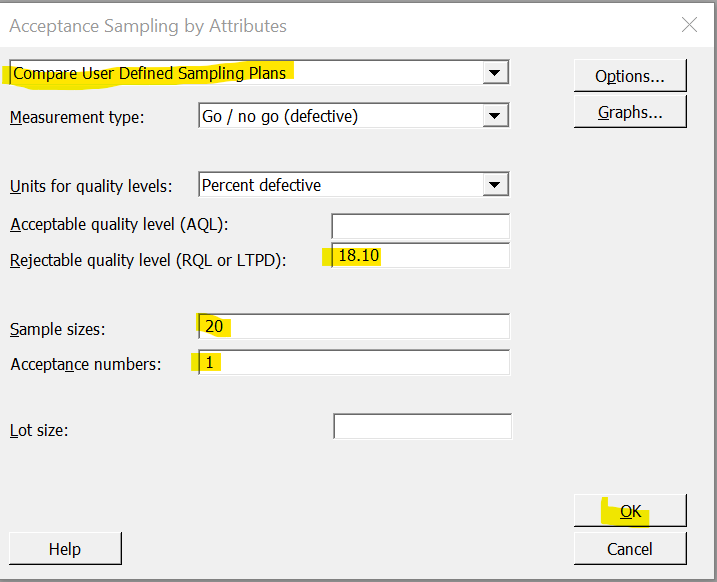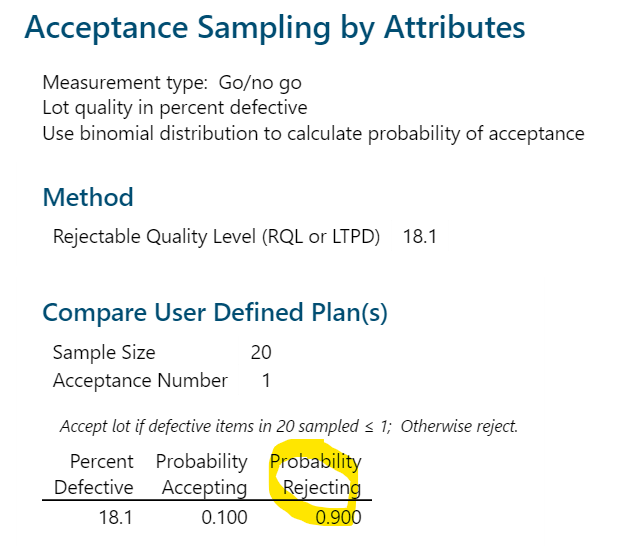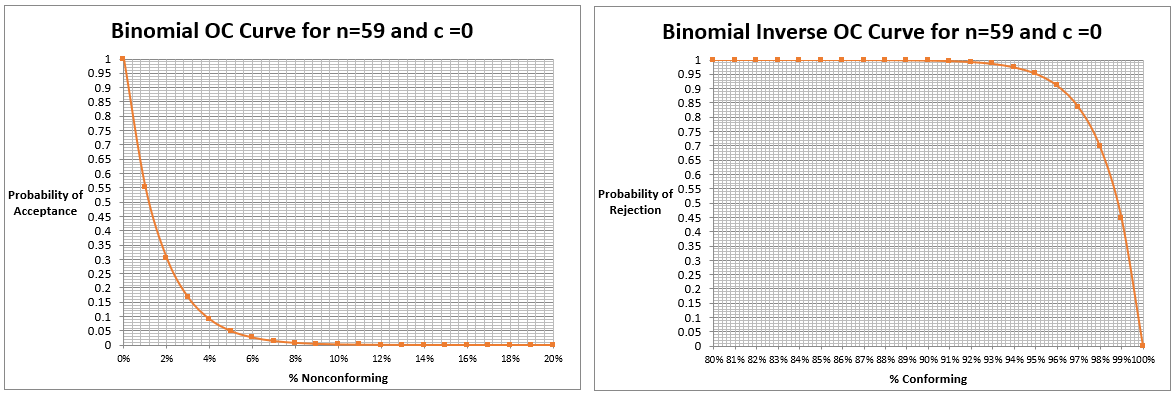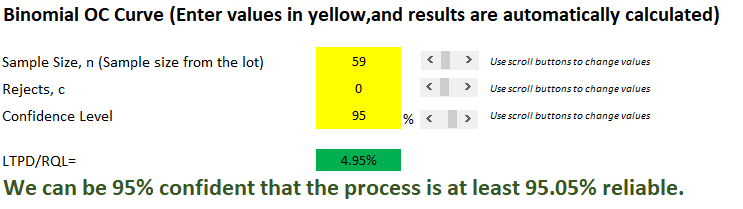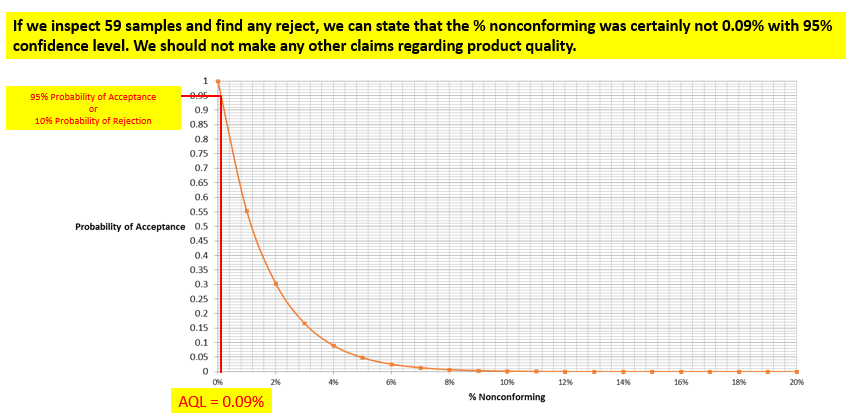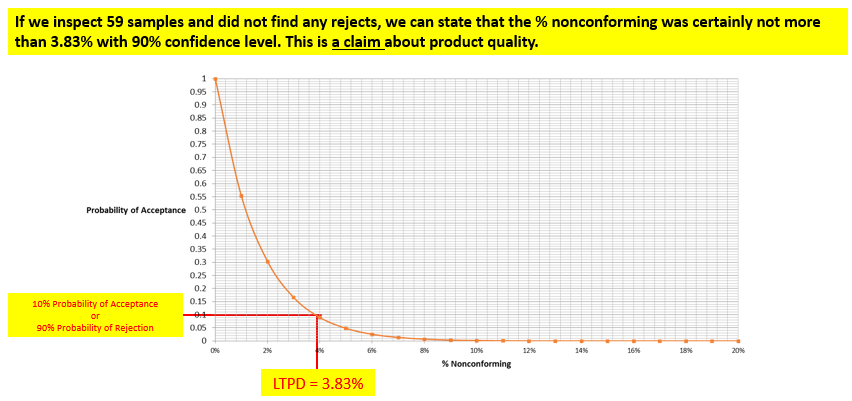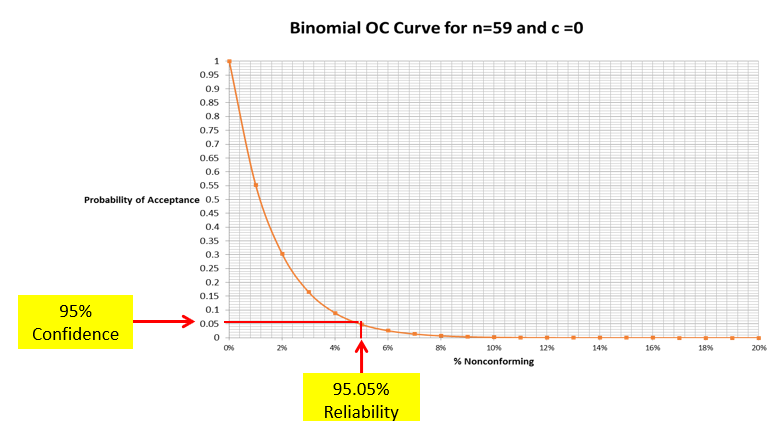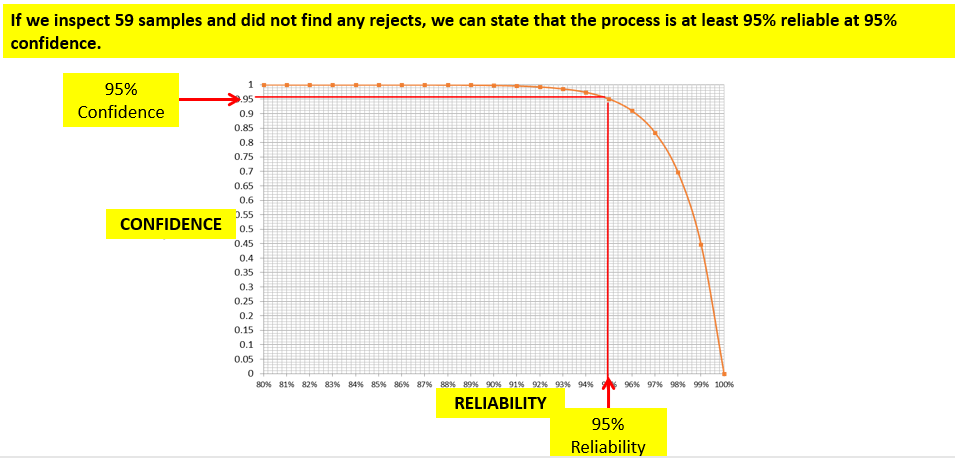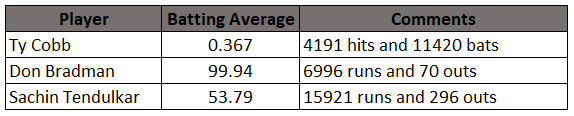
In today’s post, I am exploring the nature of probability. Is probability an intrinsic feature of events that evolves over time, or is it something else entirely? My view is that probability is best understood as a measure of an observer’s uncertainty that can change as new information becomes available, rather than as a property that events themselves possess.
Probability is not an intrinsic property of events that evolves over time. It is a measure of an observer’s uncertainty that changes as the observer gains new information.
This insight becomes clear when we consider what happens before and after an event of interest occurs. You might assign a 35% probability that your favorite team will win their championship match in 2025 based on their team, coaching staff, recent performance, and other factors. When your team does indeed win the championship in 2025, you no longer speak of a 35% chance afterward. You know they won, so your uncertainty about whether your team would capture the 2025 title is gone. The event itself has not changed. What has changed is simply your information about it.
This example reveals something fascinating. The event does not have a probability that flows through time. Your favorite team winning the 2025 championship does not possess an inherent “35% chance property” that somehow transforms into a “100% chance property” when they claim victory. Rather, probability expresses your epistemic state. It expresses what you know and do not know about the event. As your knowledge updates, so does the probability you assign.
Before the season, the probability of 35% captured your uncertainty given incomplete information about how this specific championship race would unfold. After they win, your uncertainty about whether your team won the 2025 championship disappears because you have complete information about this particular outcome. The players were competing and making decisions throughout the season, but your knowledge of the final result was incomplete and then became complete. Probability tracks this change in knowledge, not a change in the event itself.
Your favorite team winning the 2025 championship is a singular, unrepeatable event. This singularity principle applies to every event, whether it is the outcome of a coin toss or whether you miss a train. Even when we consider the 2026 championship, that represents a completely separate event requiring its own probability assessment. You might again assign some probability to your team winning in 2026, but this concerns a different season with different players, different opponents, and different circumstances. The fact that your team won in 2025 provides information that might influence your assessment of their 2026 chances, but each championship stands as a distinct event with its own associated uncertainty.
Different philosophical schools interpret probability in various ways. Frequentists focus on long-run patterns, while others emphasize physical propensities in systems. I adopt the Bayesian perspective here, which treats probability as quantifying an observer’s degree of belief about uncertain outcomes. This framework excels at handling partial information and belief updating as new evidence arrives.
The Bayesian approach formalizes how rational observers should revise their beliefs. You start with a prior probability based on available information. When new evidence arrives, Bayes’ theorem shows how to calculate an updated posterior probability, which then serves as the prior for the next update. Certainty represents probability at its extremes (belief of 1 or 0), but most real-world knowledge involves intermediate probabilities reflecting justified but incomplete information.
Let us return to the championship example with this framework in mind. Your initial 35% probability assignment reflects partial knowledge about the 2025 season that remains open to revision. When your favorite team wins the championship, your belief updates to certainty: probability 1. This transition represents a shift in your epistemic state, not a change in some objective property of the championship outcome. The probability assigned to the event changes only because your information changes.
Your team winning the 2025 championship might influence how you assess their chances for future seasons, but each championship represents a separate event. The 2026 championship is not the same event as the 2025 championship because it involves different circumstances, different player development, different opponents, and different strategic decisions that create their own uncertainty. Your experience from the 2025 season provides information for assessing future championship races, but the probability you assign to the 2026 contest addresses a distinct event with its own epistemic challenges.
Once an event’s outcome becomes known, assigning forward-looking probabilities to that specific completed event loses predictive meaning. However, probabilities retain important roles in other contexts. We use explanatory probabilities to reason about hidden causes of observed effects, and counterfactual probabilities to explore alternative scenarios for learning and decision-making. These applications all involve managing uncertainty about things we do not fully know.
Some philosophers argue for objective chances embedded in physical reality, claiming that the world itself has genuine probabilistic features. Even these can be understood through a Bayesian lens as rational betting odds conditioned on our best current knowledge about physical laws and initial conditions. From this epistemic perspective, probability fundamentally reflects our relationship to knowledge and uncertainty, not immutable features of external events.
Understanding probability as observer-dependent rather than event-dependent has practical implications. It explains why different people can reasonably assign different probabilities to the same event because they possess different information. It clarifies why probabilities can seem to “change” as we learn more: our knowledge evolves while events themselves follow deterministic or genuinely random processes. Most importantly, it positions probability as a dynamic tool for rational reasoning under uncertainty rather than a mysterious property that events carry through time.
Finally, it is important to recognize that while our beliefs may remain probabilistic, our decisions in the real world must ultimately resolve into binary choices. We decide to carry an umbrella or not, to take the highway or not, to treat a patient or not. Practical action demands that we collapse our probabilistic beliefs into definitive commitments. This reinforces that probability serves as a bridge between uncertainty and action, not as a property that events carry through time.
Final Words:
This epistemic view of probability transforms how we think about uncertainty and prediction. Rather than searching for probabilities “out there” in the world, we recognize them as tools for managing our own knowledge and ignorance.
As Pierre Simon Laplace eloquently put it: “Probability theory is nothing but common sense reduced to calculation.”
Once we embrace probability as a measure of what we know rather than what events are, we can use it more effectively as the rational tool it was always meant to be.
Always keep learning…