

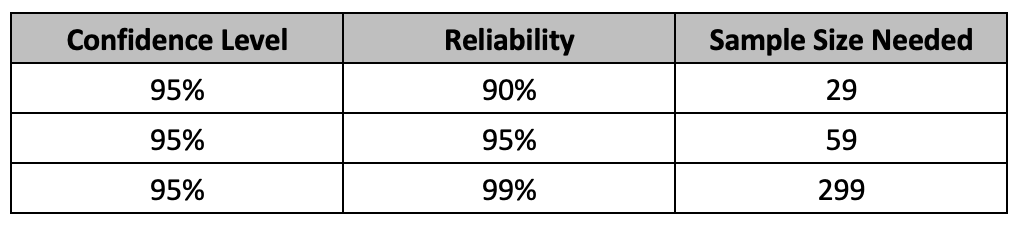
In today’s post, I am looking at some practical suggestions for reducing sample sizes for attribute testing. A sample is chosen to represent a population. The sample size should be sufficient enough to represent the population parameters such as mean, standard deviation etc. Here, we are looking at attribute testing, where a test results in either a pass or a fail. The common way to select an appropriate sample size using reliability and confidence level is based on success run theorem. The often-used sample sizes are shown below. The assumptions for using binomial distribution holds true here.
The formula for the Success Run Theorem is given as:
n = ln(1 – C)/ ln(R), where n is the sample size, ln is the natural logarithm, C is the confidence level and R is reliability.
Selecting a sample size must be based on risk involved. The specific combinations of reliability and confidence level should be tied to the risk involved. Testing for higher risk profile attributes require higher sample sizes. For example, for a high-risk attribute, one can test 299 samples and if there were no rejects found, then claim that at 95% confidence, the product lot is at least 99% conforming or that the process that produced the product is at least 99% reliable.
Often time, due to several constraints such as material availability, resource constraints, unforeseen circumstances etc., one may not be able to utilize required sample sizes needed. I am proposing here that we can utilize the stress/strength relationship to appropriately justify the use of a smaller sample size while at the same time not compromise on the desired reliability/confidence level combination.
A common depiction of a stress/strength relationship is shown below for a product. We can see that as long as the stress distribution does not overlap with the strength distribution, the product should function with no issues. The space between the two distributions is referred to as the margin of safety. Often, the product manufacturer defines the normal operating parameters based on this. The specifications for the product are also based on this and some value of margin of safety is incorporated in the specifications.
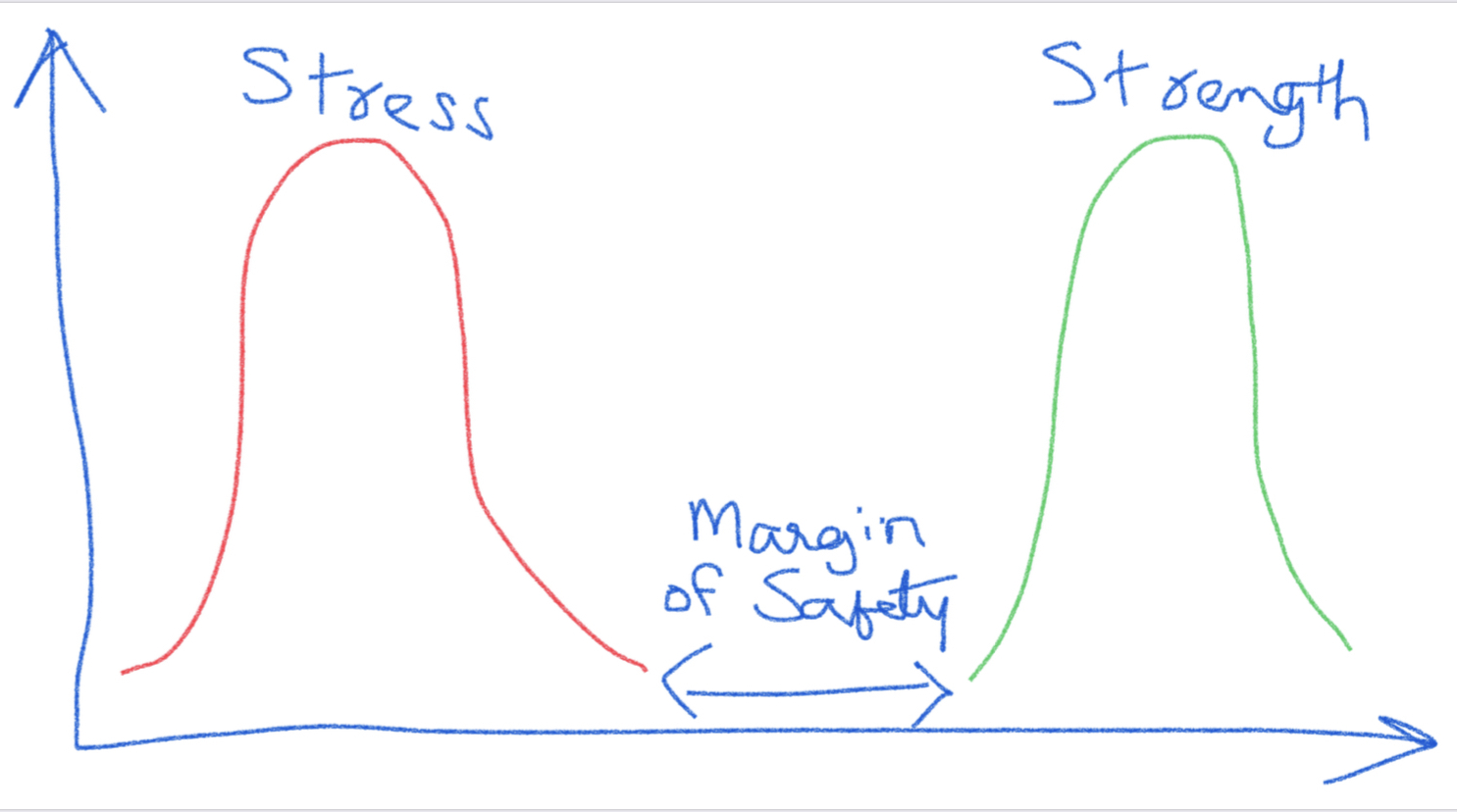
For example, let’s say that the maximum force that the glue joint of a medical device would see during normal use is 0.50 pound-force, and the specification is set as 1.5 pound-force to account for a margin of safety. It is estimated that a maximum of 1% can likely fail at 1.5 pound-force. This refers to 99% reliability. As part of design verification, we could test 299 samples at 1.5 pound-force and if we do not have any failures, claim that the process is at least 99% reliable at 95% confidence level. If the glue joint is tested at 0.50 pound-force, we should be expecting no product to fail. This is after all, the reason to include the margin of safety.
Following this logic, if we increase the testing stress, we will also increase the likelihood for failures. For example, by increasing the stress five-fold (7.5 pound-force), we are also increasing the likelihood of failure by five-fold (5%) or more. Therefore, if we test 60 parts (one-fifth of 299 from the original study) at 7.5 pound-force and see no failures, this would equate to 99% reliability at 95% confidence at 1.5 pound-force. We can claim at least 99% reliability of performance at 95% confidence level during normal use of product. We were able to reduce the sample size needed to demonstrate the required 99% reliability at 95% confidence level by increasing the stress test condition.
Similarly, if we are to test the glue joint at 3 pound-force (two-fold), we will need 150 samples (half of 299 from the original study) with no failures to claim the same 99% reliability at 95% confidence level during the normal use of product. The rule of thumb is that when aiming for a testing margin of safety of ‘x,’ we can reduce the sample size by a factor of ‘1/x’ while maintaining the same level of reliability and confidence. The exact number can be found by using the success run theorem. In our example, we estimate at least 95% reliability based on the 5% failures while using 5X stress test conditions, when compared to the original 1% failures. Using the equation ln(1-C)/ln(R), where C = 0.95 and R = 0.95, this equates to 59 samples. Similarly for 2X stress conditions, we estimate 2% failures, and here R = 0.98. Using C = 0.95 in the equation, we get the sample size required as 149.
If we had started with a 95% reliability (5% failures utmost) and 95% confidence at the 1X stress conditions, and we go to 2X stress conditions, then we need to calculate the reduced sample size based on 10% failures (2 x 5%). This means that the reliability is estimated to be 90% at 2X stress conditions. Using 0.95 for confidence and 0.90 reliability, this equates to a reduced sample size of 29.
A good resource to follow up on this is Dr. Wayne Taylor’s book, “Statistical Procedures for the Medical Device Industry”. Dr. Taylor notes that:
An attribute stress test results in a pass/fail result. However, the unit is exposed to higher stresses than are typical under normal conditions. As a result, the stress test is expected to produce more failures than will occur under normal conditions. This allows the number of units tested to be reduced. Stress testing requires identifying the appropriate stressor, including time, temperature, force, humidity and voltage. Examples of stress tests include dropping a product from a higher height, exposing a product to more cycles and exposing a product to a wider range of operating conditions.
Many test methods contained in standards are in fact stress tests designed to provide a safety margin. For example, the ASTM packaging standards provide for conditioning units by repeated temperature/humidity cycles and dropping of units from heights that are more extreme and at intervals that are more frequent than most products would typically see during shipping. As a result, it is common practice to test smaller sample sizes. The ASTM packaging conditioning tests are shown… to be five-times stress tests.
It should be apparent that if the product is failing at the elevated stress level, we cannot claim the margin of safety, we were going for. We need to clearly understand how the product will be used in the field and what the normal performance conditions are. We need a good understanding of the safety margins involved. With this approach, if we are able to improve the product design to maximize the safety margins for the specific attributes, we can then utilize a smaller sample size than what is noted in the table above.
Always keep on learning. In case you are interested, my last post was Deriving the Success Run Theorem:
Note:
1) It’s commonly used to depict a distribution using +/-3 standard deviations (σ). This is a practical way to visualize a distribution.
2) The most prevalent representation of a distribution often resembles a symmetrical bell curve. However, this is a simplified sketch and not intended to accurately represent the true data distribution, which may exhibit various distribution shapes with varying degrees of fit.
Discover more from Harish's Notebook - My notes... Lean, Cybernetics, Quality & Data Science.
Subscribe to get the latest posts sent to your email.

I suppose you’ve heard of the, Abilene paradox ( https://en.wikipedia.org/wiki/Abilene_paradox ) It’s a pragmatical or behavioural paradox, where one makes a difference between what one beliefs (or thinks) what’s happening and what one actually does. We used to show the movie at quality training sessions.
Quality is about relationships, not about quantities. The very concept of “quality” is used for things one cannot measure. One cannot measure quality into products. It might lead to analysis paralysis.
It’s usually better to try to limit the consequences of failures. In The Netherlands there used to be a saying: “May God give us our daily bread and a yearly flooding”. Once people think they’re safe behind a dyke or dam, they don’t prepare for flooding any-more. Flooding becomes less often, but the consequences bigger.
At Rijkswaterstaat – responsible for water safety in The Netherlands – they were proud to say that the change of flooding was reduced from 1 every 200 years to 1 every 400 years (this was before climate change). I said: “the change is still 1, but the consequences are quadrupled”. Nowadays, they’re planning for flooding, by giving rivers space to flood. (And off course, now drought has become a challenge).
Products usually don’t fail because of sample size and tests, but because of assumptions – also a kind of attributes – one makes about the behaviour of people and their systems. Test assumptions, not products.
LikeLike
Hi Harish,
Your article is very insightful. I am presenting a talk at he ASEM conference in Denver on October 25 about “Optimal Design Verification” or how to choose the right sample size that balances risks. I think this topic is relevant, and I have added a link to the article. Talk about Just In Time publishing!
This is probably not a novel approach, as Taylor observed in his handbook. However, the key is to have a credible model that relates the probability of failure to stress level. There are many such models suggested in the field of Accelerated Life Testing and Analysis (ALTA). One model can be chosen over others if either (a) there is solid theory of physics of failure to support the model, or (b) a multi-level, multi-failure ALTA shows that model being more likely than competing models.
But I could be wrong about this. I’d be interested to discuss this further with you and other readers.
Thank you!
Andy
LikeLiked by 1 person
Hi Andy,
Thank you for your kind response and using my article in the conference. I do agree that understanding of a failure model is quite important and agree with your comments. This understanding is a must to clearly state what the factor of safety is.
My thinking is that the approach needed related to the point of reference. You can either start from where things break down/fail or from where we define the process window to be. In the second case, we need to identify the performance/process range and go outside the range by a certain factor and show that there are no failures. This may not be the edge of failure but will be a “known safe operating range”.
Many ways to get to Rome.
-Harish
LikeLike
Hi Andy,
Can you also share the link to your conference presentation if possible? Thank you!
Looking forward,
Harish
LikeLike
Hi Harish,
Please email me at andrew.sleeper@hach.com, and I will send the documents to you.
Thanks,
Andy
LikeLike