The FAA (Federal Aviation Administration) defines visual inspection as “the process of using the unaided eye, alone or in conjunction with various aids, as the sensing mechanism from which judgments may be made about the condition of a unit to be inspected.”
Visual inspection, especially 100% visual inspection, is used by many industries as part of their Quality or Risk Management programs. Sometimes, as the last resort, companies implement 100% inspection if the residual risk is deemed to be high. I had previously written about inspection here and here.
In this post, I will discuss visual inspection in detail, value of 100%, 200% or 300% inspection (100% inspection followed by 100% inspection by one or two inspectors), factors impacting visual inspection, and end with a story from the field.
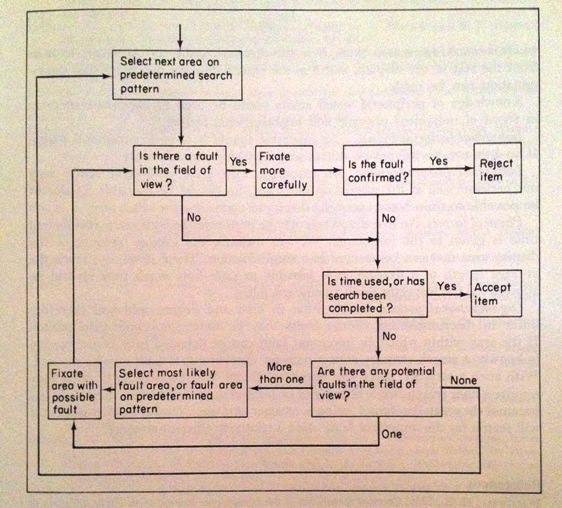
Flow chart for visual inspection:
The figure below is taken from the book “Human Reliability in Quality Control”, edited by C G Drury and J G Fox.
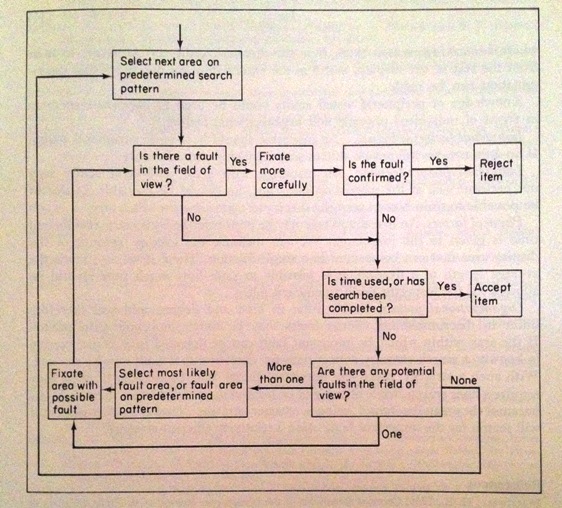
Figure 1: Flow chart for visual inspection
In “Visual Inspection: A Review of the Literature” by Judi E See (a Sandia National Laboratories report), visual inspection is detailed in a five step process:
In general, there are five basic steps that must be completed during an inspection task:
- Set up: obtain procedures or work instructions, items to be inspected, and equipment needed for inspection
- Present: prepare item for inspection (e.g., by installing in holding fixture or microscope)
- Search: examine item for possible defects
- Decide: compare potential defect against standards to determine if it exceed the standards
- Respond: accept or reject the item based on the decision made in Step 4, mark the item as needed, and complete required paperwork
Effectiveness of 100% Inspection:
Juran, one of the giants of Quality, has written that, based on his studies performed on Inspector accuracy, 100% inspection is about 87% effective. Juran gave the following formula to calculate the Accuracy of an Inspector.
Accuracy of inspector = percent of defects correctly identified = (d-k)/(d-k+b)
where d = defects reported by the inspector
k = number of good units rejected by the inspector
d-k = true defects found by the inspector
b = defects missed by the inspector, as determined by check inspection
d-k+b = true defects originally in the product
This brings us to the next question, is 200% or 300% inspection effective?
From a pure probability standpoint, multiple inspections are indeed effective. For example, if we determine that 100% inspection is 85% effective (as an example), we can then calculate the probability of rejects being identified by at least one inspector.
P(rejects being identified by at least one inspector) = 1 – (1- e)^n
where e = inspection effectiveness (85% in the example)
n = number of 100% inspections (3 in the example)
Thus, we can determine that the 300% inspection with an inspection effectiveness value of 85% is 99.7% effective. In other words, 300% inspection will still result in 0.3% of the bad product to be missed.
The number of rejects caught by 100% inspection can be found by the following calculation.
# of rejects caught = N * p * e
where N = Lot size
p = % non-conforming product
e = inspection effectiveness
Please note that all this math and probability may not hold water in real world. This is because we were treating the three events of inspection as independent events. In real life, Inspector 3 might assume that Inspector 1 and 2 are extremely good, and that he does not need to pay full attention. Unfortunately, this bad logic may be used by Inspector 1 or 2, and in the worst case by all three inspectors. This type of “leaning on the other inspector” thinking breaks the independent event assumption we used in our probability calculation.
Factors impacting visual inspection:
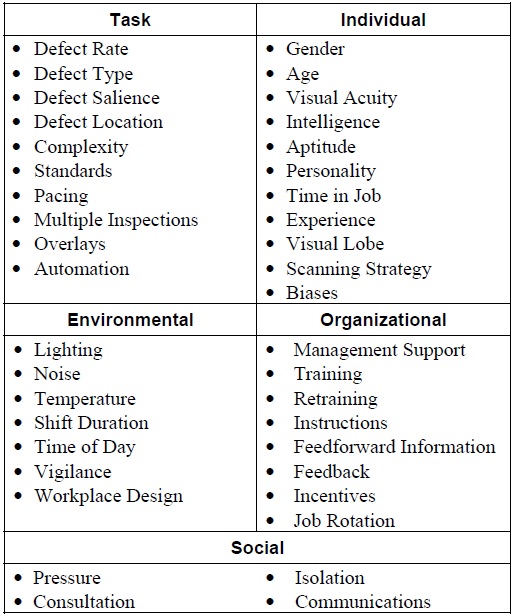
In the wonderful report from Judi E See, we can also find a detailed list of factors that can impact inspection performance. One can find that any Attribute Agreement Analysis that is performed on visual inspection can be quickly challenged due to the high number of factors that need to be considered. On the contrary, this also explains why 100% inspection still produces rejects.
Table 1 – Factors impacting visual inspection performance
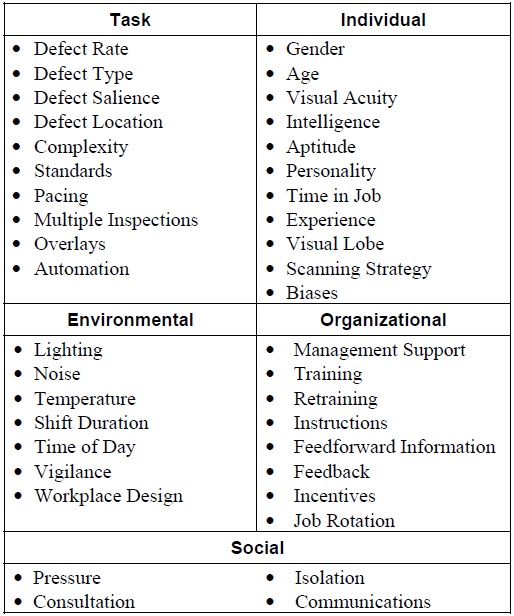
I will discuss some of these factors that I found to be interesting below.
Defect Rate:
Interestingly, as the defect rate goes down the inspection accuracy suffers. Alternatively, as the defect rate goes up, the inspection accuracy improves. In other words, if your lot has low number of defects, there is a really small likelihood of finding any rejects.
Multiple 100% Inspections:
I discussed briefly about multiple inspections above. The report however brings interesting “twists” to multiple inspections. First off, the report does find that multiple 100% inspections, especially for critical rejects, are better than just one 100% inspection. The report then goes on to discuss five possible methods to incorporate multiple 100% inspections.
Each inspector inspects only half the batch in parallel
Two accepts: both inspectors inspect every item and both must accept an item for the system to accept it
Two rejects: both inspectors inspect every item and both must reject an item for the system to reject it
Re-inspect accepts: Inspector 2 inspects only those items accepted by Inspector 1
Re-inspect rejects: Inspector 2 inspects only those items rejected by Inspector 1
Gender:
There has been a misconception in the manufacturing industries that women are better at visual inspection than men. The corollary is that men are better at assembly operations than women. The report found that such notions are indeed false. There is no proven correlation between gender and inspection effectiveness.
Workplace design:
In “Sound Practices for Consistent Human Visual Inspection” by James A Melchore, the author states the following.
Recent studies by Knapp (9) and Budd (8) indicate that inspection with a light intensity of 550 foot candles will increase detection of particulates. Knapp’s data indicates that the use of 550 foot candles light intensity, combined with an 18% gray background, enabled 95% detection of a 150-μm particle 95% of the time.
Final Thoughts and the Story of the Box of Rejects:
Harold F. Dodge has stated that “You cannot inspect quality into a product.” The feedback loop should be as small as possible for an inspection activity to be value adding. This feedback also has the benefit of improving the process since the operator is made aware of the issue almost immediately. The best case is to have poke-yoke or mistake proofing such that mistakes do not happen at all.
I do not have a source for the story below. I heard this story below that contrasts the western and eastern thinking.
A famous American company thought that they would try to have a component manufactured in Japan on a trial basis. As part of the qualification activities, the American company clearly wrote that they will accept only three rejects per 10,000 parts.
When the delivery came from Japan, they found two boxes accompanied by a letter from the Japanese firm.
“Dear Sir,
We are having a hard time meeting your requirements. We had to manufacture the three defective parts separately to meet your requirements. Please reconsider your position.”
The second box that was much smaller in size was clearly labeled as noted in the letter “THREE REJECTS AS REQUIRED. DO NOT USE FOR PRODUCTION.”
Always keep on learning…